Authors: Securonix Labs
Introduction
Supervised learning methods are used for summarizing information contained within data to make predictions. In order to do so, they require a set of outputs (labels) and inputs. The objective is to understand the relationship between them and predict the output on a new unseen input. As opposed to unsupervised learning where the goal is much more subjective due to working with unlabeled data, the goal of supervised learning is much better defined as it involves the prediction of a response variable based on a set of previously defined labels.

https://www.slideshare.net/myles_harrison/machine-learning-for-humans
Labeled data is very difficult to obtain primarily due to the need for human discernment to provide information related to an event. With rapidly evolving threats, we need core security expertise in the complicated underlying process to dispose of (label) events. As labeling is generally a manual process, it is often time-consuming and expensive for an organization to undertake. By ensuring that we have the most important events sent to an analyst, we can optimize analyst’s time and proceed to capture the process by which each event was disposed of through the use of supervised learning methods. It is also important to have labeled data that is representative of both threat and non-threats to enable the method to discern the differences between categories.
Supervised learning models can perform only as well as the process generating the labels. If the logic in obtaining them is simple, then the process can be captured in a straightforward way. For example, if there are labels generated by a set of rules that can be acquired through queries, then any supervised learning approach can only do as well as the mechanism by which the labels are generated. Understanding the labeling process is critical and should be assessed prior to leveraging supervised learning.
Supervised learning methods capture the thought process of an analyst by encoding its complex logic within a corresponding model. The model summarizes inferred relationships between the input features and the dispositions (labels) and might not always be transparent, explainable in human terms if such relationships are not-linear and convoluted. The encoded thought process is later used to dispose of new events as a threat or non-threat by assigning a corresponding probability reflecting the risk associated with an event.
While binary classification as threat or non-threat is very popular and useful in processes such as response automation, supervised learning can also facilitate prioritization of events as they are streaming in to ensure that an analyst receives the most important ones first. For a model that is only partially built with limited amount of data, which is typical in cybersecurity, a substantial portion of the incoming events might fall in a grey area between threat and non-threat, but we can order them by their threat probability to significantly reduce time to detection for high-risk events. This reduces analyst’s response time to critical events substantially and frees more of their time to investigate new and emerging threats.
Feature Engineering
Feature Engineering is the process of selecting and transforming useful data elements from raw data that represent the best the problem being solved by the supervised learning method. When the raw data is ingested, many attributes are either irrelevant, or redundant, or don’t provide enough informational content by themselves and need to be transformed appropriately into actionable features. The transformation might involve deriving several features from a single attribute or combining multiple indicators together in order to maximize generalization capability of the supervised learning method.
For example, using the whole request URL below as a feature might be too specific and not generalize well, but extracting the protocol and port number as separate features and recognizing public suffix as Dynamic DNS service could have sufficient predictive power to identify malicious request:
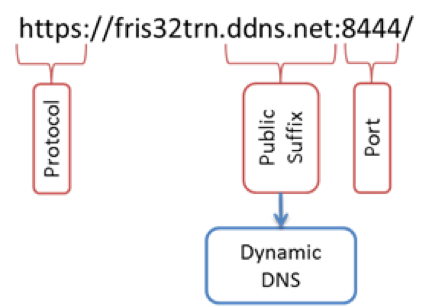
While feature redundancy and relevance can be automatically established with statistical methods like Principal Component Analysis (PCA) or Multiple Correspondence Analysis (MCA), feature engineering generally requires security domain expertise to ensure the features are meaningful and can be indicative that an event is a threat. Feature engineering is often the most time-consuming stage of applying machine learning methods, as it requires a good deal of effort and cross-collaboration between security and data science teams to ensure that features are useful.
Overfitting
The first, training phase of the process of building a supervised learning model involves fitting a model to a portion of the available historical data. Here we seek to learn the parameters that minimize a suitable loss function between the fitted model and the true labels. We can evaluate the model by measuring its performance on the remaining data in a testing phase:

In order to ensure the model generalizes well to new data, we need to avoid overfitting the training data. By increasing the complexity of the model, we can keep decreasing the error on the training sample, but at some point the model can become too specific to the training data, losing generalization quality, and the error on the test sample starts to increase. Finding the optimum where both training and test errors are low is the bias-variance tradeoff:

https://onlinecourses.science.psu.edu/stat857/node/160
In real applications, training sample cannot be used to optimize the model, because then it becomes a part of the model and cannot serve as an independent validation. Instead, various data-splitting techniques are employed for cross-validation to select the optimal model.
Online Learning
Typically, supervised learning applications are deployed in offline, or batch mode, as described above: the model is trained on a static dataset and then applied to new data to predict the outcome. The model has to be rebuilt from scratch every time there is a change in the training dataset. While it works well for datasets that don’t change often and are small enough for the model to be rebuilt as needed, many modern cybersecurity applications operate on very large and diverse datasets and require models to be updated in seconds, not days, to reflect a fast-changing threat landscape.
Online learning algorithms address this problem by continuously updating the model as data is streaming in. Online learning model adapts as each new event is presented to it, responding to the needs of an analyst in near real time. Stream processing of the incoming data, incremental model updates, and a lack of need to store ever-expanding training datasets required for batch processing give online learning methods tremendous computational advantage, without sacrificing the accuracy of prediction.
Email Classifier
Effective detection of data exfiltration requires a substantial degree of process automation. Amongst a multitude of event attributes to consider, behavioral anomalies to assess, a variety of exfiltration schemes and ever-increasing volume of digital communications, detecting malicious activity is a daunting task. Faced with an overwhelming amount of false positives and the pressure to minimize business impact, even the most experienced analyst is bound to miss quite a few data exfiltration attempts. Considering cybersecurity talent shortage and the cost of scaling up analyst resources, automated analytics is the only answer to this problem. We can apply supervised learning to capture the thought process of the analyst investigating data exfiltration cases and apply it to new events to predict the potential outcome. These predictions can be used to prioritize the event queue to let an analyst focus on the most critical ones, as well as to automatically dismiss low-risk instances. This approach reduces time to discovery for critical events and allows the organization to achieve cost-efficient risk reduction by balancing risk tolerance against available analyst resources. In addition, it distills cumulative knowledge of experienced analysts to provide actionable guidance for the novices.
To develop Email Classifier, we examined cases of data exfiltration via email that were investigated and labeled by the analysts. A combination of event attributes, user metadata, and behavioral indicators from our threat models based on unsupervised learning produced just over 30 features that held potential relevance to data exfiltration. Transformation of some of the features for better generalization followed by the statistical feature importance analysis reduced the number of useful features to 14. These features were then used to train a Random Forest model, a popular supervised learning algorithm selected for its accuracy, resistance to overfitting and straightforward tuning that lends itself well to an automated analytics.

Random Forest is an ensemble learning method.
The model was tuned using 10-fold cross-validation on 18,000 labeled data points. Despite seriously imbalanced training data (only 5% labels were positive), predictions on 7,600 test cases (excluded from training) were extremely accurate, as shown in the confusion matrix below:
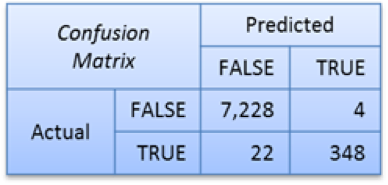
99.7% accuracy and Matthews correlation coefficient of 0.96 are solid indicators of the Email Classifier’s success in capturing the thought process of an analyst and applying it to new, unlabeled cases to predict the likelihood of them being a threat.
In this example of the classifier application, we were fortunate to have a large number of labeled cases to train the model. While the model is portable between different customers, the context at each new customer is different, as well as the analyst’s expertise that the algorithm is trying to capture; therefore, the classifier has to be trained in the specific customer environment. To evaluate classifier performance when only a fraction of labeled data is available, as is most likely to be the case in real-world applications, we simulated training dataset growing over time. Impressively, in only two weeks of training classifier achieved 70% of the maximum accuracy; at 6 weeks, it was over 90%:

The curve in blue represents the sensitivity of the classifier over time as a fraction of maximum performance achieved on the complete training dataset.
Even as the classifier is being initially trained with new data streaming in, it is increasingly useful in prioritizing cases pending investigation to allow an analyst to get to the most critical ones in a shorter amount of time.
Other chapters in this series:
Introduction – Data Science: A Comprehensive Look
Ch 1 – SIEM 2.0: Why do you need security analytics?
Ch 2 – Data Science: Statistics vs. Machine Learning
Ch 3 – Unsupervised Learning: Combining Security and Data Science
Ch 4 – Supervised Learning: Capturing The Thought Process Of An Analyst