
Ch 5 - Feature Engineering: Science or Art?
Security Analytics

Authors: Securonix Labs
Feature Engineering is the process of selecting and extracting useful, predictive signals from data. The goal is to create a set of features that best represent the information contained in the data, producing a simpler model that generalizes well to future observations. Methods range from statistical analysis of feature distribution in the dataset, especially in supervised learning where it can be correlated to the target classes, to nontrivial transformations and synthesis of desired characteristics based on the business domain knowledge. The latter part, domain expertise, is the top circle in the Venn diagram of data science:
In cybersecurity, domain expertise is also a key missing ingredient in the skillset of the new generation of data scientists flocking into security analytics in recent years. In the field, we used to have conversations with SOC analysts on sensors to use and the meaning of analytics results to security; now, it’s mostly discussions with freshly minted data science teams on algorithms to use and distributions to apply. There is a significant gap between the two camps, and insufficient amount of talent crossing it. Both statistical and security knowledge are absolutely critical for the successful implementation of machine learning in cybersecurity, and their importance is most pronounced in the feature engineering process, the science and the art of it.
Data exploration is a critical step in identifying features with high information content necessary to build a stable model with good predictive power. Whether using visual analytics tool like Tableau, statistical package like R or a simple Excel spreadsheet, we want to find features (or combinations of thereof) that reflect or approximate implicit signals in the data, and avoid irrelevant or redundant features that represent the noise and lead to overfitting. Obvious extremes, like features with a single unique value (zero variance predictors) and features where each value is unique in the dataset (e.g. transaction ID in the log) are absolutely uninformative and should be excluded. On the other hand, near-zero variance predictors, where in addition to a prevailing common value there is a minor fraction of different values, might prove valuable in identifying exotic classes or clusters, or in a severely imbalanced dataset (https://tgmstat.wordpress.com/2014/03/06/near-zero-variance-predictors/).
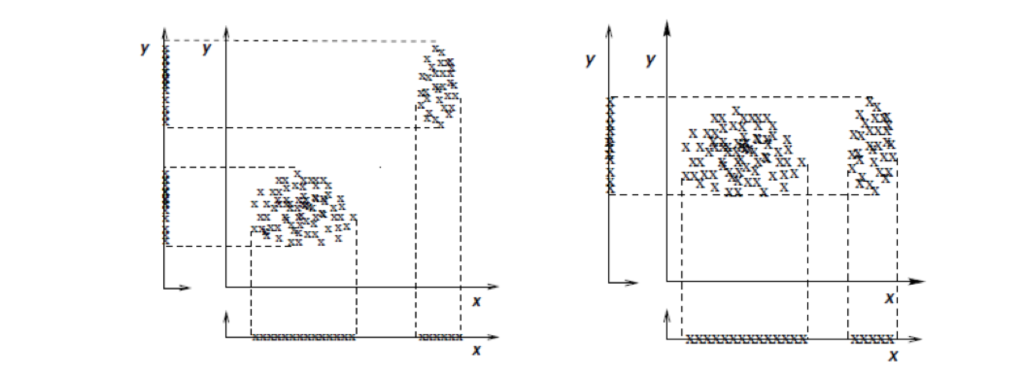
Example of redundant feature (left: feature y provides the same information as x) and irrelevant feature (right: feature y does not discriminate between the clusters defined by x). http://www.jmlr.org/papers/volume5/dy04a/dy04a.pdf
In general, feature selection is more difficult in unsupervised learning, since the criteria for selection is defined by the clusters or patterns detected, which in turn depends on the feature set selected. In supervised learning, class labels guide the selection through the feature to class correlation. There’s a variety of simple to use methods for univariate selection, such as Pearson Correlation Coefficient for linear relationships, Distance Correlation for non-linear, or entropy-based Mutual Information. There can also be situations where individual features are not very informative by themselves, but become strong predictor as an aggregate, requiring multivariate statistical methods to be applied.
Which brings us to the actual engineering part of the process: transforming and extracting new information from the original features to create better predictors. Principal Component Analysis (PCA) is a popular method to extract statistically significant information from the data by transforming original features into a new space with lower dimensionality. Selecting only the most significant components cuts off noise and emphasizes meaningful combinations of features. For categorical features, Multiple Correspondence Analysis (MCA) can be used, and for non-linear relationships between features various transformations can be explored (https://www.datasciencecentral.com/profiles/blogs/feature-engineering-data-scientist-s-secret-sauce-1).
The range of methods outlined above approach feature engineering from data-centric point of view, without any consideration for a business domain the model is applied to. This data-driven approach has a strong appeal to data scientists because it’s portable and deterministic, and provides a ready-to-go set of tools to tackle new problems. Its success over several large classes of problems in AI led to advances in automated Feature Learning and exuberant popularity of Deep Learning.
In cybersecurity, data-driven approach has its merits, but its applications are limited by the nature of the data itself: heterogeneous and often complex data fields; scarce, imbalanced and sometimes ambiguous labels; inconsistent event sequences; changing trends and other imprints of human behavior. Brute-forcing these problems is likely to result in an unstable solution with weak predictive power and high false positive rate, or a very specific niche predictor that provides very little value for broad security applications. There are plenty of market strugglers and failed startups to illustrate both scenarios of attacking security problems with the purely mathematical approach.
Domain expertise is essential in focusing on the features relevant to the cybersecurity problem at hand, and in creating new or enriching existing features to amplify the information contained in the data over the noise. Business insight is a powerful aid in engineering the right representation of the data, but it’s often use case oriented and can introduce a serious bias into the model if left unchecked. Considering several incongruous models and cross-validating results should help to stay out of the trap of “fitting facts into theory”.
To demonstrate a value of feature engineering, let’s start with a simple example of fraudulent activity detected over the period of 1.5 years. Out of 28K transactions during this time, 24 have been marked as fraudulent (less than 0.1%), as shown on the timeline below:
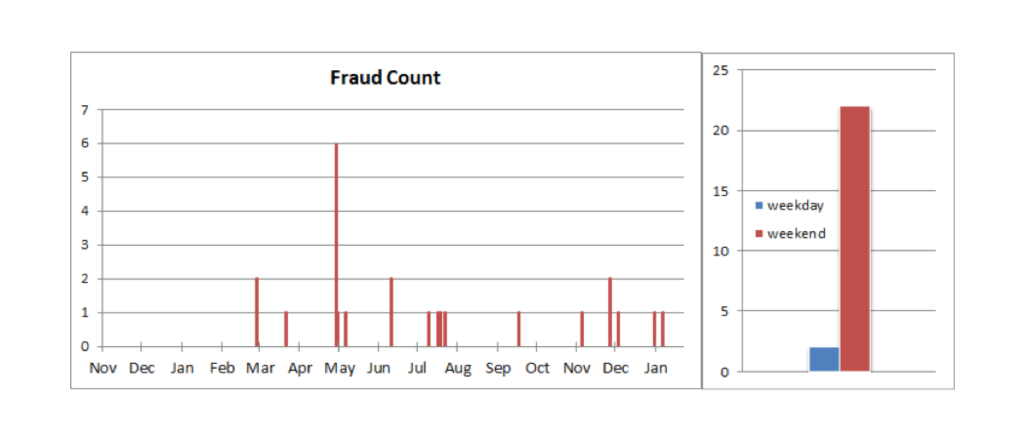
Timeline of fraudulent activity (left) and its breakdown by day of the week (right)
And all we have is a timestamp of the transaction to go on. No matter how deep your neural network is, or how big your random forest is, training it on this kind of data using raw timestamps is not going to produce any meaningful predictions. On the other hand, applying just a tiny bit of domain expertise – realization that fraud is more likely to occur after hours or on the weekend – results in a new-perfect predictor: weekend indicator, extracted from the timestamp, correctly predicts 22 out of 24 cases.
There are many ways to extract relevant information or enrich original features with the context that provide greater insight into the data, resulting in a model that more accurately reflects the underlying process than a purely data-driven model. Protocol and port extracted from the request URL to pinpoint the type of communication used; DHCP log lookup to replace dynamic IP address with the hostname uniquely identifying device involved; file type inferred from the extension to substitute for the actual file name; and so on. The importance of new feature can be determined for each selected model, and refined model then used to discover more hidden gems. There’s no preset recipe for finding the most informative features: it’s an art form based on the knowledge of the process that generated the data, business meaning and security implications of that process, and considerable data wrangling efforts to expose its key attributes.
Let’s look at a more complex case of feature engineering employed by our DGA Detection algorithm. Domain Generation Algorithm (DGA) is an evasion technique employed by the malware to circumvent blacklist- and signature-based defenses. DGA is designed to generate a large number of domain names to defeat blocking, while at the same time minimize collisions with legitimate, human-named domains. Here are some examples of the DGA domains (http://osint.bambenekconsulting.com/feeds/):

To detect DGA, the algorithm attacks its design principle, specifically looking for names with high information entropy. Domain name is first broken into words using Depth-First Search (DFS) against a multilingual set of dictionaries, and the combination with the lowest overall entropy is chosen as the best dictionary representation of the domain name. Word entropy is modeled after Shannon entropy
![]()
where p_i is a ratio of the number of dictionary words of length i over total number of possible character permutations in the string of the same length. Here’s an example of the calculations:
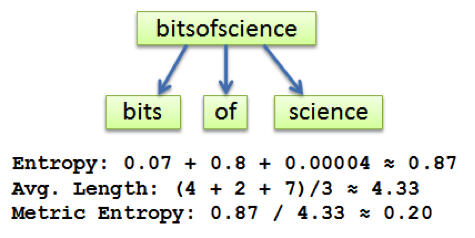
The longer the word, the smaller the entropy. Normalized to the average word length, metric entropy is a good measure of randomness of the domain name and has been used as one of the features to train DGA detection algorithm.
The charts below show distributions of domain names along the entropy and domain name length axes for legitimate domains (Alexa’s Top 1M), as well as GOZ and Cryptolocker malware families. Legitimate, human-created domains are clustered in the area of low entropy, while GOZ domains are clearly separated with significantly higher entropy and narrow length range. Most of the Cryptolocker domains have higher entropy too, but there is still a substantial overlap with the area of legitimate domains, and additional features are needed to separate them:
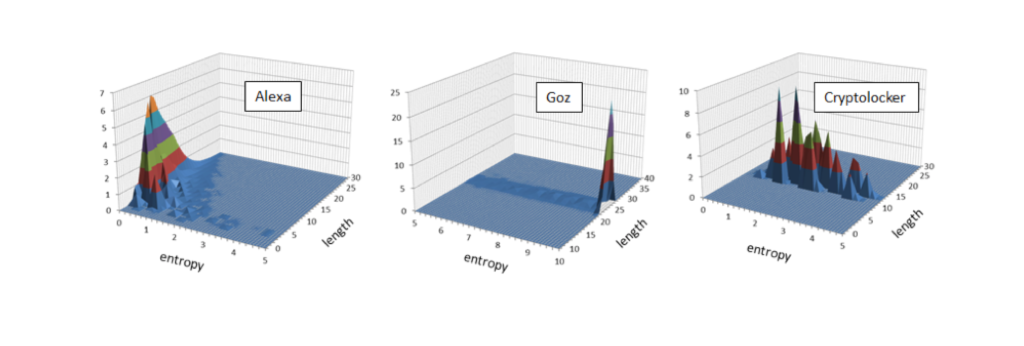
To improve detection accuracy, we added top-level domain, dictionary matched and the number of numerics to the list of features, and trained Random Forest on the combination of domains from Alexa Top 1M and from multiple malware feeds (generously provided by John Bambenek). The resulting classifier detected 98% of DGA domains with less than 1% false positives.
Diligent data exploration and intelligent feature creation go a long way towards building an efficient predictor. The science of statistics combined with the art of insightful application of domain expertise gives feature engineering the power to uncover the information hidden in customarily complex and noisy cybersecurity data.
Deep Learning: Automated feature generation
Introduction – Data Science: A Comprehensive Look
Ch 1 – SIEM 2.0: Why do you need security analytics?
Ch 2 – Data Science: Statistics vs. Machine Learning
Ch 3 – Unsupervised Learning: Combining Security and Data Science
Ch 4 – Supervised Learning: Capturing The Thought Process Of An Analyst
Ch 5 – Feature Engineering: Science or Art?



